1Show Lab, National University of Singapore 2TikTok
Published as a conference paper at ICLR 2026
In recent years, integrating multimodal understanding and generation into a single unified model has emerged as a promising paradigm. While this approach achieves strong results in text-to-image (T2I) generation, it still struggles with precise image editing. We attribute this limitation to an imbalanced division of responsibilities. The understanding module primarily functions as a translator that encodes user instructions into semantic conditions, while the generation module must simultaneously act as designer and painter, inferring the original layout, identifying the target editing region, and rendering the new content. This imbalance is counterintuitive because the understanding module is typically trained with several times more data on complex reasoning tasks than the generation module.
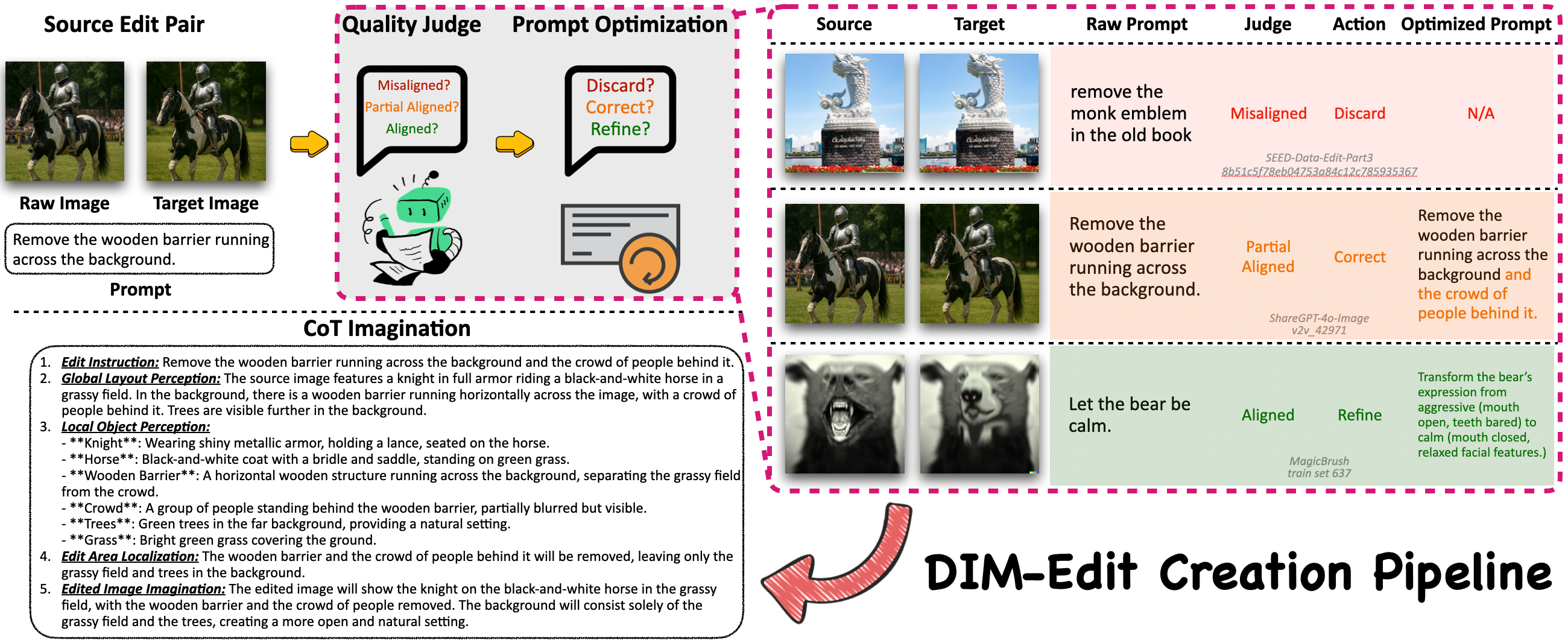
To address this issue, we introduce Draw-In-Mind (DIM), a dataset comprising two complementary subsets: (i) DIM-T2I, containing 14M long-context image-text pairs to enhance complex instruction comprehension; and (ii) DIM-Edit, consisting of 233K chain-of-thought imaginations generated by GPT-4o, serving as explicit design blueprints for image edits. We connect a frozen Qwen2.5-VL-3B with a trainable SANA1.5-1.6B via a lightweight two-layer MLP, and train it on the proposed DIM dataset, resulting in DIM-4.6B-T2I/Edit.
Despite its modest parameter scale, DIM-4.6B-Edit achieves SOTA or competitive performance on the ImgEdit and GEdit-Bench benchmarks, outperforming much larger models such as UniWorld-V1 and Step1X-Edit. These findings demonstrate that explicitly assigning the design responsibility to the understanding module provides significant benefits for image editing. Our dataset and models are available at github.com/showlab/DIM.
By offloading the design decision to the understanding module, DIM-4.6B-Edit applies the requested edit precisely while leaving non-edited regions intact, across common editing scenarios.




Add a person walking along the dirt path, facing toward the ocean, wearing a backpack and casual hiking clothes.




Add a small wooden cabin with a chimney near the edge of the forest on the right side of the image.




Add a small wooden cabin to the left side of the image, near the tree, blending naturally with the landscape.




Change the person's shirt color to blue.




Change the animal's fur color to a solid shade of brown.




Change the background from the snow to a beach setting.




Remove the child standing near the edge of the water.




Remove the sheep in the foreground.




Remove the seaplane on the shoreline.




Replace the deer in the image with a lion standing majestically in the same forest setting, under the glowing golden light and light snowflakes.




Replace the mountain goat in the image with a rabbit.




Replace the horse in the image with a cat.




Transfer the image into a colourful ceramic mosaic-tile style.




Transfer the image into a traditional ukiyo-e woodblock-print style.




Transfer the image into a folded-paper origami art style.
ImgEdit Overall
By default, GPT-4o serves as the external designer. All models are evaluated using GPT-4.1.
| Model | Add | Adj. | Ext. | Rep. | Rem. | Back. | Sty. | Hyb. | Act. | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| MagicBrush | 2.84 | 1.58 | 1.51 | 1.97 | 1.58 | 1.75 | 2.38 | 1.62 | 1.22 | 1.83 |
| Instruct-P2P | 2.45 | 1.83 | 1.44 | 2.01 | 1.50 | 1.44 | 3.55 | 1.20 | 1.46 | 1.88 |
| AnyEdit | 3.18 | 2.95 | 1.88 | 2.47 | 2.23 | 2.24 | 2.85 | 1.56 | 2.65 | 2.45 |
| UltraEdit | 3.44 | 2.81 | 2.13 | 2.96 | 1.45 | 2.83 | 3.76 | 1.91 | 2.98 | 2.70 |
| Step1X-Edit | 3.88 | 3.14 | 1.76 | 3.40 | 2.41 | 3.16 | 4.63 | 2.64 | 2.52 | 3.06 |
| BAGEL | 3.56 | 3.31 | 1.70 | 3.30 | 2.62 | 3.24 | 4.49 | 2.38 | 4.17 | 3.20 |
| UniWorld-V1 | 3.82 | 3.64 | 2.27 | 3.47 | 3.24 | 2.99 | 4.21 | 2.96 | 2.74 | 3.26 |
| Janus-4o | 3.35 | 3.35 | 2.25 | 3.01 | 2.18 | 3.32 | 4.71 | 2.49 | 4.04 | 3.19 |
| GPT-4o-Image | 4.61 | 4.33 | 2.90 | 4.35 | 3.66 | 4.57 | 4.93 | 3.96 | 4.89 | 4.20 |
| DIM-4.6B-Edit (Ours) | 4.09 | 3.47 | 2.30 | 4.00 | 3.43 | 3.87 | 4.92 | 2.85 | 4.08 | 3.67 |
ImgEdit Designer Ablation
† The default setting. The first row uses no external designer.
| Designer | Add | Adj. | Ext. | Rep. | Rem. | Back. | Sty. | Hyb. | Act. | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| – | 3.53 | 3.23 | 2.01 | 3.49 | 1.47 | 3.42 | 4.79 | 2.35 | 3.64 | 3.10 |
| Qwen2.5-VL-3B | 3.80 | 3.24 | 2.03 | 3.89 | 3.21 | 3.52 | 4.92 | 2.71 | 4.05 | 3.49 |
| Qwen2.5-VL-7B | 3.95 | 3.35 | 2.25 | 3.85 | 3.31 | 3.57 | 4.88 | 2.81 | 4.02 | 3.55 |
| MiMo-VL-7B | 3.95 | 3.32 | 2.20 | 3.75 | 2.46 | 3.82 | 4.88 | 2.52 | 3.93 | 3.43 |
| InternVL3.5-8B | 3.98 | 3.40 | 2.05 | 4.14 | 3.30 | 3.84 | 4.94 | 2.77 | 3.89 | 3.59 |
| GLM-4.1V-9B | 3.95 | 3.27 | 2.23 | 3.90 | 2.64 | 3.81 | 4.92 | 2.23 | 4.02 | 3.44 |
| GPT-4o† | 4.09 | 3.47 | 2.30 | 4.00 | 3.43 | 3.87 | 4.92 | 2.85 | 4.08 | 3.67 |
@misc{zeng2025draw,
title = {Draw-In-Mind: Rebalancing Designer-Painter Roles in Unified Multimodal Models Benefits Image Editing},
author = {Zeng, Ziyun and Zhang, David Junhao and Li, Wei and Shou, Mike Zheng},
year = {2025},
eprint = {2509.01986},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2509.01986}
}























