Method
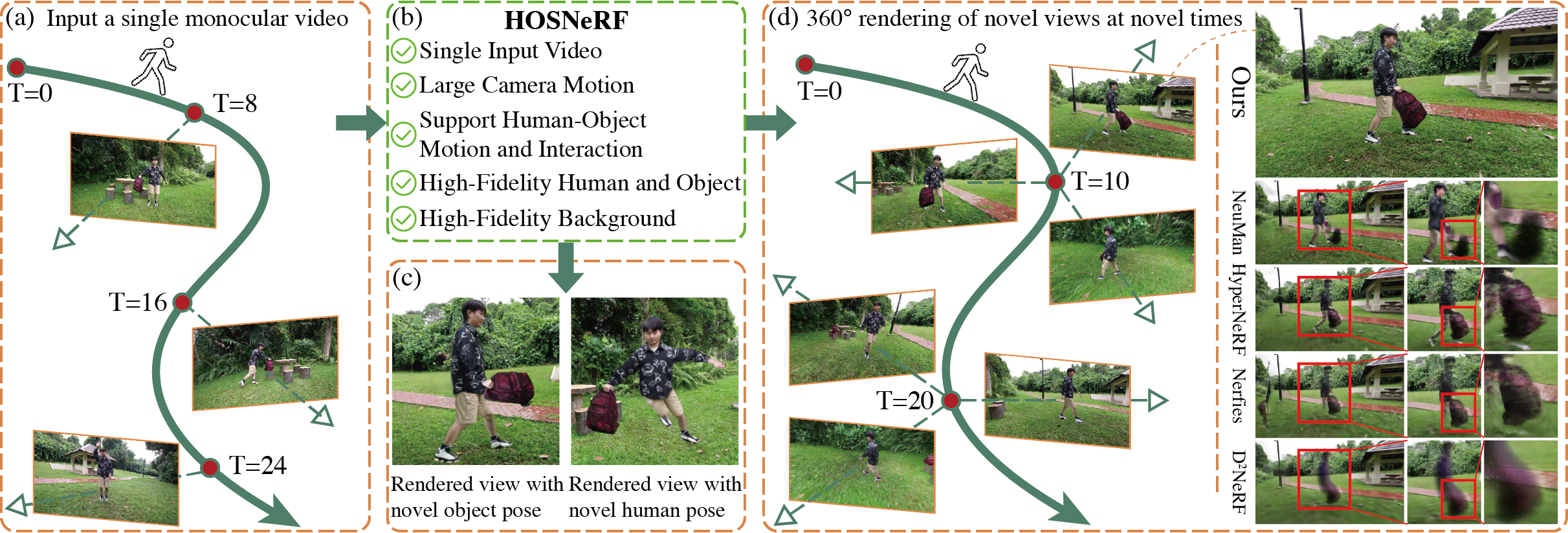
Our HOSNeRF (b) takes a single monocular in-the-wild video (a) as input, and creates high-fidelity 360° free-viewpoint rendering of all scene details (dynamic human body, objects, and background) at any time (d). Our method enables rendering views with novel object poses and novel human poses as shown in (c), and produces high-fidelity dynamic novel view synthesis results at novel timesteps, with significant improvements over SOTA approaches as shown in (d).
Abstract
We introduce HOSNeRF, a novel 360° free-viewpoint rendering method that reconstructs neural radiance fields for dynamic human-object-scene from a single monocular in-the-wild video. Our method enables pausing the video at any frame and rendering all scene details (dynamic humans, objects, and backgrounds) from arbitrary viewpoints.
The first challenge in this task is the complex object motions in human-object interactions, which we tackle by introducing the new object bones into the conventional human skeleton hierarchy to effectively estimate large object deformations in our dynamic human-object model. The second challenge is that humans interact with different objects at different times, for which we introduce two new learnable object state embeddings that can be used as conditions for learning our human-object representation and scene representation, respectively.
Extensive experiments show that HOSNeRF significantly outperforms SOTA approaches on two challenging datasets by a large margin of 40% ∼ 50% in terms of LPIPS. Compelling examples of 360° free-viewpoint renderings from single videos are provided in the following video.