Instruction-Guided Video Editing
Kiwi-Edit supports a wide range of text instruction-based video editing tasks. Select a category below to view results.
Reference Image-Guided Video Editing
Kiwi-Edit can transfer visual attributes from a reference image to the target video. The model extracts background or subject information from the reference image while preserving the original motion and structure of the video.
Quantitative Results
OpenVE-Bench
Table 2. OpenVE-Bench results evaluated on Gemini-2.5-Pro. Orange rows denote closed-source models and are excluded when selecting the best and second-best scores; gray rows denote open-source baselines and blue rows denote our variants. Bold and underlined scores indicate the best and second-best results among non-closed-source methods, respectively.
| Method |
#Params.
(DiT) |
#Reso. |
Overall↑ |
Global
Style ↑ |
Background
Change ↑ |
Local
Change ↑ |
Local
Remove ↑ |
Local
Add ↑ |
| Runway Aleph |
- |
1280×720 |
3.49 |
3.72 |
2.62 |
4.18 |
4.16 |
2.78 |
| VACE (Jiang et al., 2025) |
14B |
1280×720 |
1.57 |
1.49 |
1.55 |
2.07 |
1.46 |
1.26 |
| OmniVideo (Tan et al., 2025) |
1.3B |
640×352 |
1.19 |
1.11 |
1.18 |
1.14 |
1.14 |
1.36 |
| InsViE (Wu et al., 2025b) |
2B |
720×480 |
1.45 |
2.20 |
1.06 |
1.48 |
1.36 |
1.17 |
| Lucy-Edit (Team, 2025) |
5B |
1280×704 |
2.22 |
2.27 |
1.57 |
3.20 |
1.75 |
2.30 |
| ICVE (Liao et al., 2025) |
13B |
384×240 |
2.18 |
2.22 |
1.62 |
2.57 |
2.51 |
1.97 |
| DITTO (Bai et al., 2025a) |
14B |
832×480 |
2.13 |
4.01 |
1.68 |
2.03 |
1.53 |
1.41 |
| OpenVE-Edit (He et al., 2025) |
5B |
1280×704 |
2.50 |
3.16 |
2.36 |
2.98 |
1.85 |
2.15 |
| ReCo (Zhang et al., 2025) |
2.1B |
832×480 |
2.80 |
3.96 |
1.92 |
3.70 |
2.24 |
2.17 |
| UniVideo (Wei et al., 2025) |
14B |
854×480 |
3.02 |
3.67 |
2.51 |
3.79 |
2.73 |
2.40 |
| Ours (Stage-2 Instruct-Only) |
5B |
720×480 |
2.92 |
3.54 |
2.59 |
3.80 |
2.55 |
2.12 |
| Ours (Stage-2 Instruct-Only) |
5B |
1280×704 |
2.98 |
3.54 |
2.57 |
3.84 |
2.71 |
2.25 |
| Ours (Stage-3 Instruct-Reference) |
5B |
1280×704 |
3.11 |
3.72 |
2.67 |
3.91 |
2.69 |
2.55 |
RefVIE-Bench
Table 3. Comparison on RefVIE-Bench with Gemini-3-Flash as Judge Model.
| Model |
#Params.(DiT) |
Subject Reference |
Background Reference |
Overall↑ |
Identity
Consist. |
Temporal
Consist. |
Physical
Consist. |
Subj.
Avg. |
Refer.
Sim. |
Matting
Quality |
Video
Quality |
BG
Avg. |
| Runway Aleph |
- |
3.79 |
3.65 |
3.58 |
3.67 |
3.33 |
2.81 |
2.58 |
2.91 |
3.29 |
| Kling-O1 (Team et al., 2025) |
- |
4.75 |
4.66 |
4.60 |
4.67 |
3.95 |
3.21 |
2.75 |
3.30 |
3.99 |
| UniVideo (Wei et al., 2025) |
14B |
4.17 |
3.79 |
3.59 |
3.85 |
3.13 |
2.55 |
2.28 |
2.65 |
3.44 |
| ReCo-Ref (Zhang et al., 2025) |
2.1B |
3.65 |
2.95 |
2.70 |
3.10 |
3.35 |
2.65 |
2.38 |
2.79 |
3.00 |
| Ours (Stage-3 Instruct-Reference) |
5B |
3.51 |
2.96 |
2.91 |
3.13 |
3.40 |
2.58 |
2.40 |
2.79 |
2.96 |
| Ours (Stage-3 Reference. only) |
5B |
4.28 |
3.61 |
3.55 |
3.81 |
3.33 |
2.35 |
2.08 |
2.58 |
3.40 |
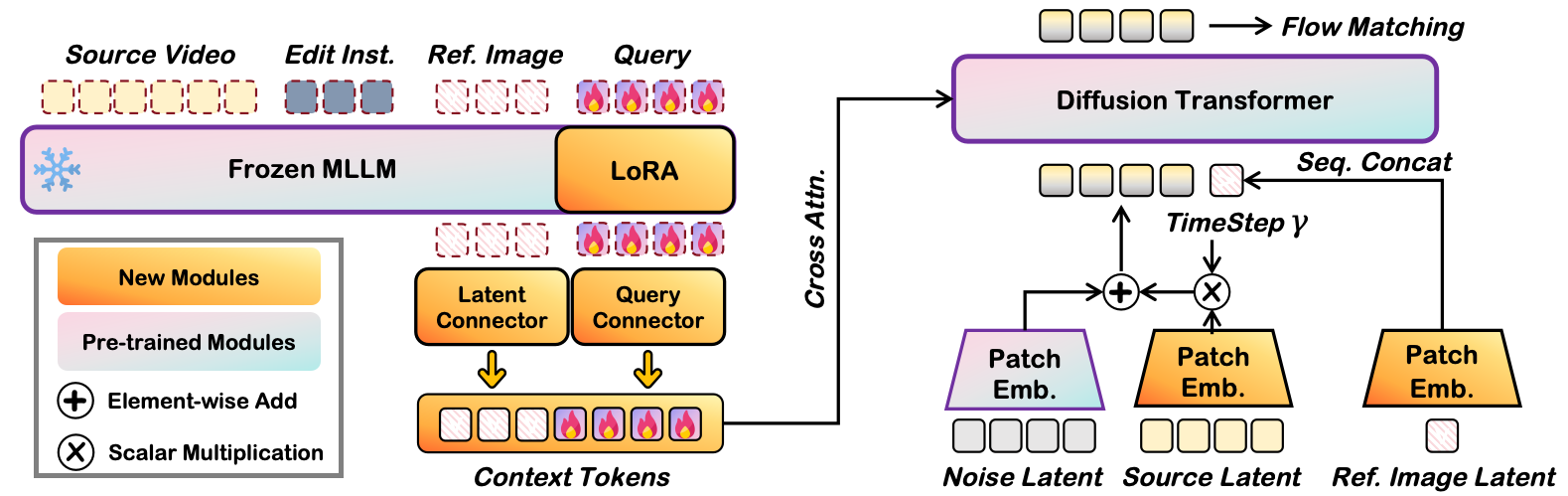
Methodology
Architecture Design
Kiwi-Edit combines a Multimodal LLM and a video diffusion transformer. Given a source video, an editing instruction, and an optional reference image, the model produces temporally consistent edited videos with controllable appearance and structure.
- Semantic Guidance: The MLLM extracts instruction and reference features to guide what should be edited.
- Structure Preservation: Source-video latents are injected into the generation process to keep motion and scene layout stable.
- Reference Fidelity: Reference visual tokens help transfer desired style and appearance details.
Training Curriculum
We train Kiwi-Edit with a simple three-stage curriculum: alignment, instruction fine-tuning, and reference-guided fine-tuning. This progressive strategy improves stability and enables strong performance across instruction and reference editing settings.
- Stage 1: Align multimodal representations between the MLLM and the diffusion backbone.
- Stage 2: Scale instruction-guided editing with large image/video data.
- Stage 3: Add reference-guided training for precise visual control.
Training Dataset
We build an automated pipeline to convert instruction triplets into reference-guided training quadruplets.
- Raw pool: 3.7M samples from Ditto-1M, ReCo, and OpenVE-3M.
- Stage 1: Quality filtering with EditScore. (Also used for instruction-only training.)
- Stage 2: Instruction-aware grounding and segmentation.
- Stage 3: Reference image synthesis for local and background edits.
- Stage 4: Semantic verification and global de-duplication.
- Final Reference Video Editing Dataset: 477K high-quality quadruplets with balanced task coverage, released for research use.
Citation
If you find Kiwi-Edit useful for your research, please cite our paper:
@misc{Kiwi-Edit2026,
title={Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance},
author={Yiqi Lin and Guoqiang Liang and Ziyun Zeng and Zechen Bai and Yanzhe Chen and Mike Zheng Shou},
year={2026},
eprint={2603.02175},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.02175},
}
 Kiwi-Edit:
Versatile Video Editing via Instruction and Reference Guidance
Kiwi-Edit:
Versatile Video Editing via Instruction and Reference Guidance