Generative models have demonstrated remarkable capability in synthesizing high-quality text, images, and videos.
For video generation, contemporary text-to-video models exhibit impressive capabilities, crafting visually stunning videos.
Nonetheless, evaluating such videos poses significant challenges. Current research predominantly employs automated metrics such as FVD, IS, and CLIP Score.
However, these metrics provide an incomplete analysis, particularly in the temporal assessment of video content, thus rendering them unreliable indicators of true video quality.
Furthermore, while user studies have the potential to reflect human perception accurately, they are hampered by their time-intensive and laborious nature, with outcomes that are often tainted by subjective bias.
In this paper, we investigate the limitations inherent in existing metrics and introduce a novel evaluation pipeline, the Text-to-Video Score (T2VScore).
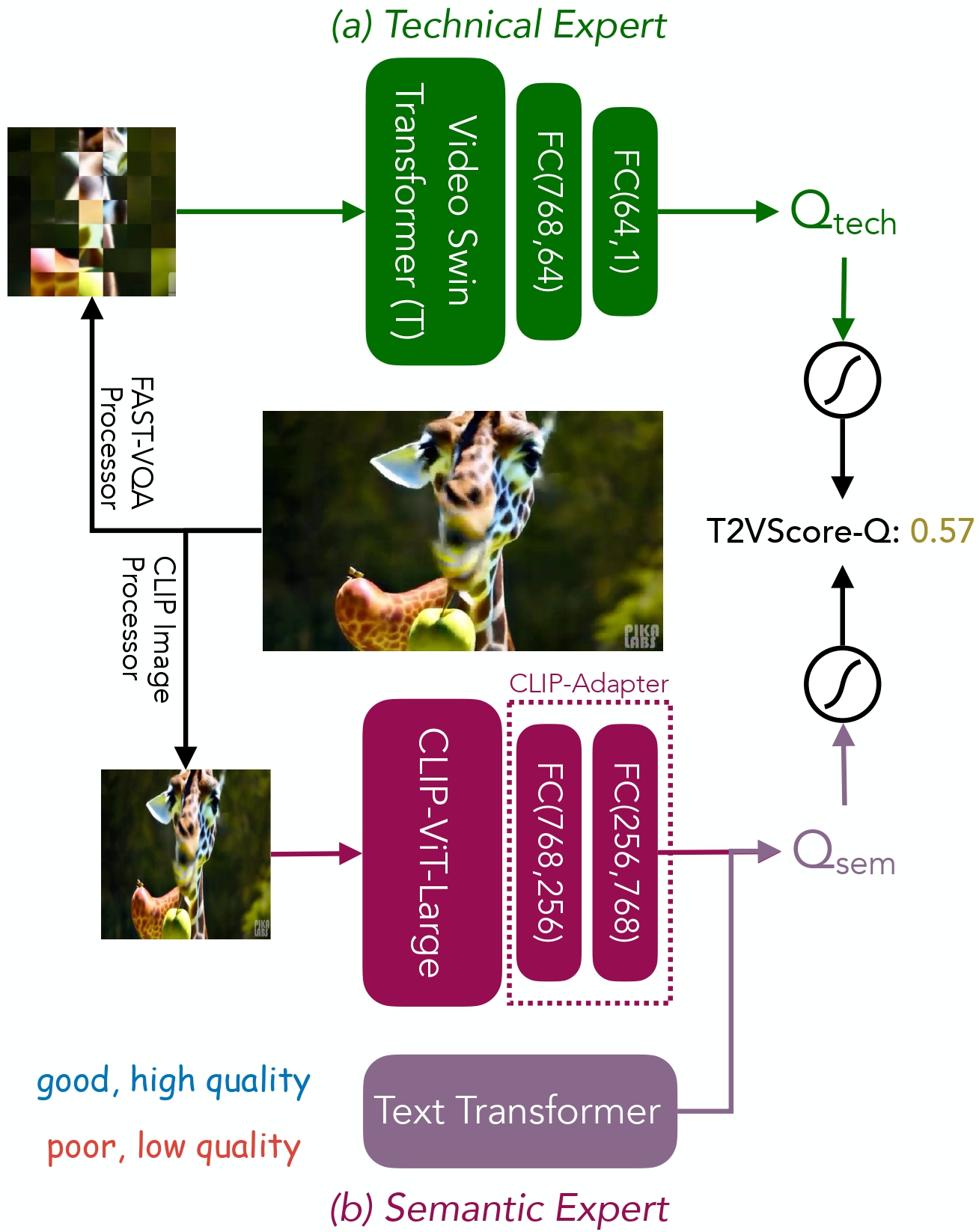
This metric integrates two pivotal criteria: (1) Text-Video Alignment, which scrutinizes the fidelity of the video in representing the given text description, and (2) Video Quality, which evaluates the video's overall production caliber with a mixture of experts.
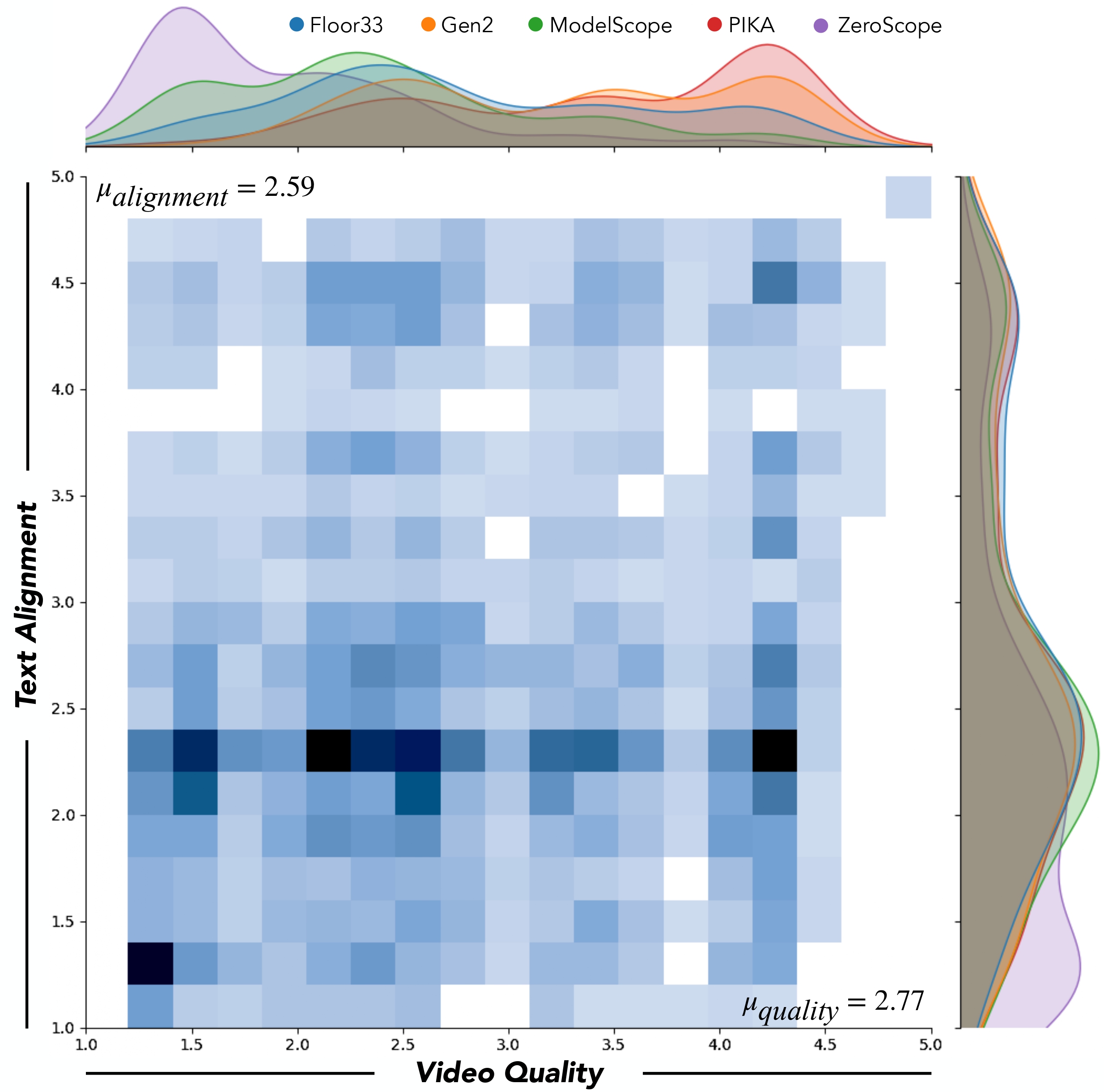
Moreover, to evaluate the proposed metrics and facilitate future improvements on them, we present the TVGE dataset, collecting human judgements of 2,543 text-to-video generated videos on the two criteria.
Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore on offering a better metric for text-to-video generation. The code and dataset will be open-sourced.